linux命令
linux shell…
deepin 尝试
sudo
curl or wget should be installed
yum -y install wget
systemctl stop nginx.service
systemctl start nginx.service
netstat -antp | grep :80
netstat -ano|findstr 8080
linux 常见
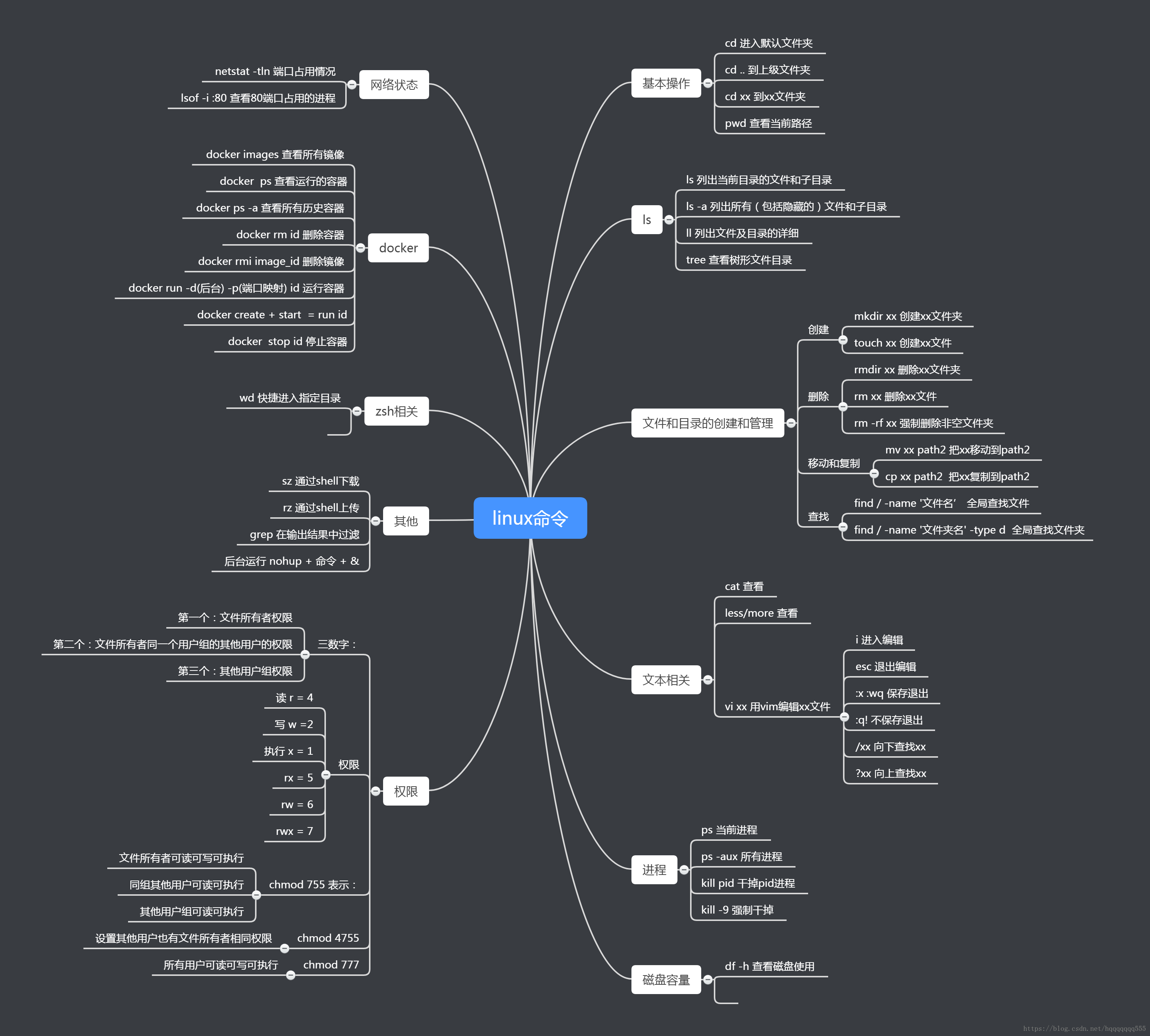
常见 shell
1 | netstat -ano | findstr 8080 |
ubuntu 静态 dns 解析
1. /etc/network/interfaces (dns-nameservers 114.114.114.114 8.8.8.8)
2. /etc/NetworkManager/NetworkManager.conf (dns=119.29.29.29)
3. /etc/resolvconf/resolv.conf.d/tail (nameserver=223.5.5.5)
host 添加
Linux 系统下 hosts 文件位置:/etc/hosts
如果是单条可以直接执行命令行:
echo “10.13.83.43 yun.xiong.cn”>> /etc/hosts
find 命令
grep 是查找匹配条件的行,find 是搜索匹配条件的文件
语法:find 起始目录 寻找条件 操作
说明:find 命令从指定的起始目录开始,递归地搜索其各个子目录,查找满足寻找条件的文件并对之采取相关的操作。
1 | find dirName -options fileName #options 是 find 的可选项,如:-name、-size、-mtime、-user、-group、-type、-perm、-exec、-o、-and、-print、-delete |
grep 常见命令
1 | grep 'test' d\* #显示所有以 d 开头的文件中包含 test 的行 |
防火墙
1 | firewall-cmd --zone=public --permanent --add-port=8080/tcp |
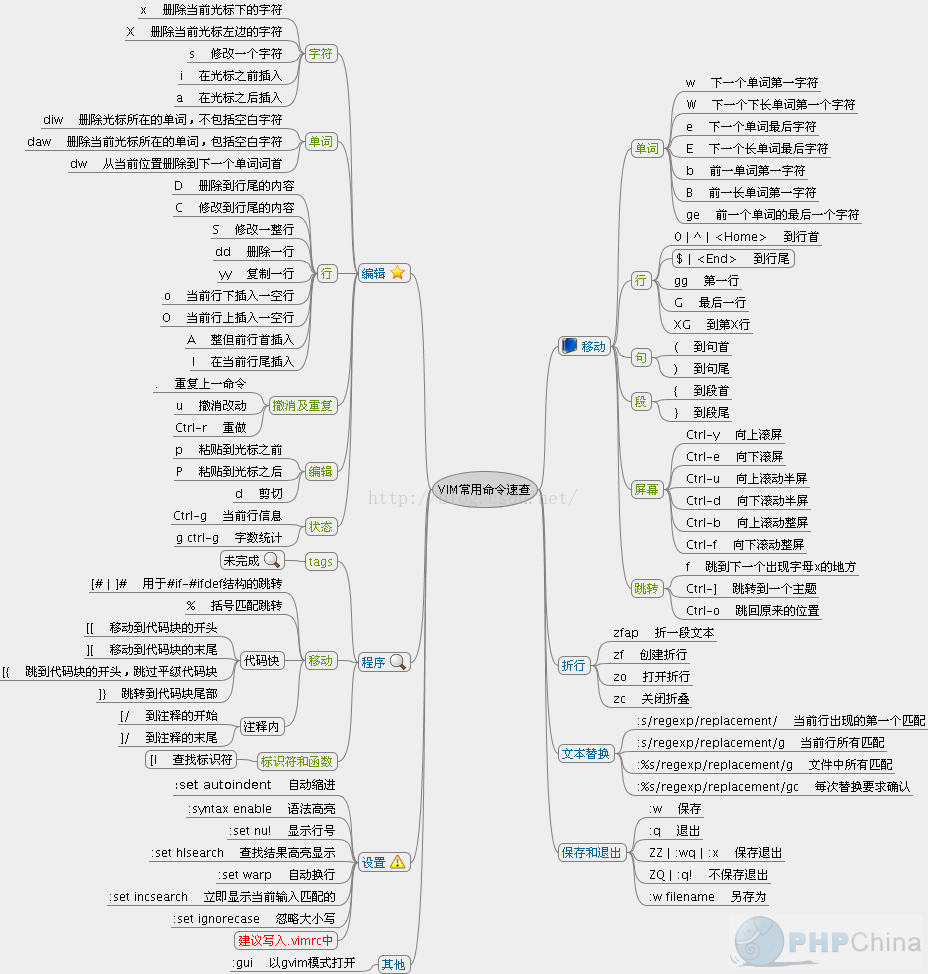
vim 命令
vimtutor
hjkl左下上有
0是跳到行首
dd删除整行
:r(replace)
使用v选择高亮的部分
使用esc进入正常模式
使用操作符 y 复制文本,使用 p 粘贴文本
使用操作符 i 插入文本,使用 u 撤销操作
w 保存不退出
w! 强制保存
wq 保存退出
wq!
q 退出
q! 强制退出
nginx 配置基础
有时会出现bind() to 0.0.0.0:20990 failed (13: Permission denied)的问题
可能是SELinux的问题
1 | getenfoce |
编译器

CPU 架构支持把二进制操作映射作为一种更容易阅读的语言——汇编语言。
虽然汇编语言非常低级,但是它可以转换为二进制代码,这种转换主要靠的是“汇编器”
高级语言–>编译器–>汇编语言–>汇编器–>机器代码(二进制代码)
汇编语言的基础知识
特点
- 与硬件相关,每一种处理器都有相应的汇编语言
- 与机器码相关,指令通常与机器码一一对应
- 家用电脑使用 intel/amd 处理器,对应 x86-x64 汇编语言
作用
- 深入理解硬件工作原理;
- 充分利用计算机特性(如 SIMD,即单指令多数据);
- 开发操作系统内核、驱动程序等;
- 优化程序
unicode 和 ascii 的区别
- ASCII 编码是 1 个字节,而 Unicode 编码通常是 2 个字节
- ASCII 是单字节编码,无法用来表示中文;而 Unicode 可以表示所有语言
- 用 Unicode 编码比 ASCII 编码需要多一倍的存储空间
“可变长编码”的 UTF-8 编码
ASCII 编码实际上可以被看成是 UTF-8 编码的一部分,所以,大量只支持 ASCII 编码的历史遗留软件可以在 UTF-8 编码下继续工作
在计算机内存中,统一使用 Unicode 编码,当需要保存到硬盘或者需要传输的时候,就转换为 UTF-8 编码。
用记事本编辑的时候,从文件读取的 UTF-8 字符被转换为 Unicode 字符到内存里,编辑完成后,保存的时候再把 Unicode 转换为 UTF-8 保存到文件
ASCII 码使用指定的 7 位或 8 位二进制数组合来表示 128 或 256 种可能的字符。标准 ASCII 码也叫基础 ASCII 码,使用 7 位二进制数(剩下的 1 位二进制为 0)来表示所有的大写和小写字母,数字 0 到 9、标点符号, 以及在美式英语中使用的特殊控制字符。其中最后一位用于奇偶校验。
Unicode 把所有语言都统一到一套编码里,这样就不会再有乱码问题了。
Unicode 最常用的是用两个字节表示一个字符(如果要用到非常偏僻的字符,就需要 4 个字节)。现代操作系统和大多数编程语言都直接支持 Unicode。
UTF-8 是 Unicode 的实现方式之一